
10% writes, 80% PK reads, 10% broadcast queries, RF=3, CL=2
One thing that struck me when reading up on Cassandra is that there is a very strong mindset in the Cassandra community around linear scalability and therefore on primary key based data models. So de-normalizing your data, such as by using materialized views is considered a best practice.
However, de-normalization has some challenges of its own. Both Cassandra-managed materialized views or any other application side managed denormalization run the risk of becoming inconsistent. And of course it does mean you're multiplying your database size.
As I wrote in my previous blog post, with the new SAI index implementation, we can now embrace using secondary indexes, as SAI indexes will perform better than previous implementations. However, the point about scaling to larger clusters still holds. Secondary indexes are local to each node. Read queries that need to use secondary indexes must be broadcast to all nodes in the cluster. If you have hundreds of nodes in your Cassandra cluster, then the query is amplified hundreds of times. In contrast, a query using the primary key is just sent to a single node (or however many nodes are needed to fullfil the requested consistency level).
So you might still argue, that to design scalable data models in a Cassandra database, your app must only use primary key based access. In reality, life isn't this black and white...
Most apps don't need to scale to hundreds of nodes
Most apps will never become the next Netflix or Apple. A simple 3 node cluster may take you further than you think. In my experience, more than 90 % of all database clusters are in this group. That's a lot of Cassandra users! All of these users can benefit from using secondary indexes as much as possible. In particular, secondary indexes will take less space, perform better, and be more consistent than a materialized view. If anything, maybe avoiding materialized views and other denormalization based designs will help these users to stay on their small and manageable 3 node cluster for longer!
But then there is the next level of apps, that need to scale a bit more than that, but are still not in the web-scale hundreds of nodes category. Those that have 6 nodes or 12 nodes in a Cassandra cluster. Again this class is the majority of the remaining population of Cassandra users. Probably truly web-scale users are 1% or less of the entire user base. In this blog post I want to elaborate more on how a Cassandra cluster scales in the presence of secondary indexes. Attached is a spreadsheet you can use to estimate the scalability characteristics for a given workload. (Btw, many other NoSQL databases will behave in a similar fashion.)
So when is it still beneficial to use secondary indexes when scaling out a Cassandra cluster?
To be clear, there's no doubt about this: When using secondary indexes, it's always preferable to scale up rather than out. Always prefer to upgrade to larger instance sizes rather than adding more nodes, if you can.
But if an app or service is successful, eventually you need to scale out. What happens now? If you add nodes, will it make things better or worse? How can a database SRE reason about this?
The key revelation is to understand is that in a multi-node cluster you only end up with a query broadcast to all nodes for the portion of read queries that actually use secondary indexes. For your writes, secondary index maintenance is 100% local to each node. And for primary key reads secondary indexes have no effect. And more precisely, any query that includes the partition key will still be efficient in a large cluster. It is only when the partition key is missing that the query is broadcast to all nodes. For a typical application one hopes that a large part of your queries are using the primary key - after all, that's what you primarily want to be using, hence the name! This means that for a typical application workloads there should be much more writes and reads that benefit from adding more nodes than the reads that don't benefit.
In short, if you add more nodes to a Cassandra cluster, then:
- All writes will benefit
- All Primary Key reads will benefit
- Queries that at least include the partition key will benefit
- Queries that use secondary indexes and use LIMIT but not ORDER BY should be neutral, as they won't be broadcast to all nodes.
We are left with the last class of queries which indeed will not scale well:
- Queries that use secondary indexes and are broadcast to all nodes will not benefit
So if we know how a given workload breaks down between the above classes, we can now model how much benefit to expect from adding more nodes to a Cassandra cluster. I have created a spreadsheet that takes as input the breakdown of different writes and reads your workload has. You can input either the percentages or absolute ops/sec, it works either way. The model assumes that all writes and reads are the same amount of work when processed on a Cassandra node. This is of course not true, but you can still use the model to just get a grasp of how far different workloads would scale if you add nodes.
Some examples
Using the scalability model spreadsheet, here are some example workloads:
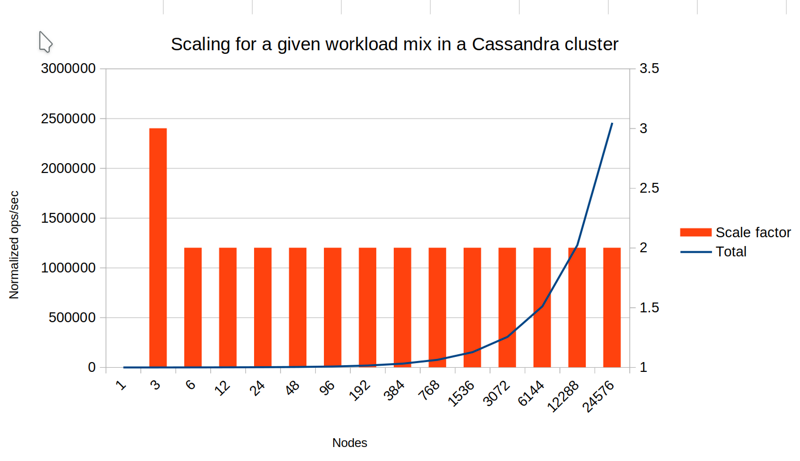
Just as a baseline, above is a workload with 100% writes, Replication Factor 1 and Consistency Level 1. The graph shows linear scalability, but since the x-axis doubles the node count each time, the ops/sec is an exponential curve as well.
Next is the same but with Replication Factor 3 and Consistency Level 2.
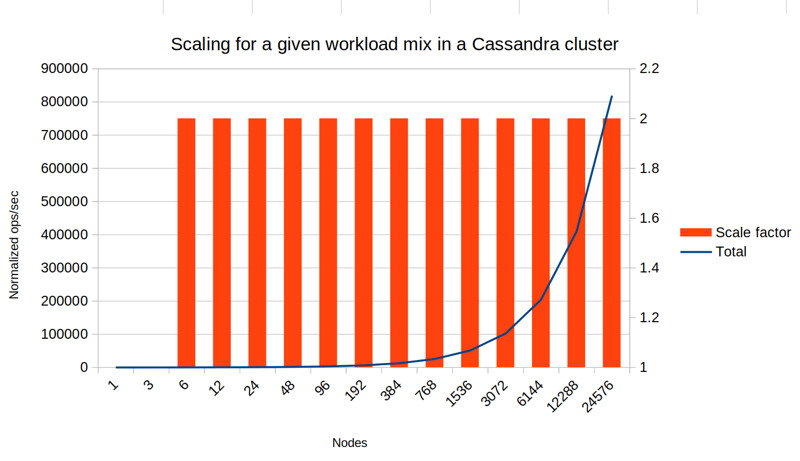
It's exactly the same, except that the step from 1 nodes to 3 doesn't do anything. With RF=3 all writes go to all 3 nodes. But going from 3 to 6, and so on, we again get 2x more performance for each step.
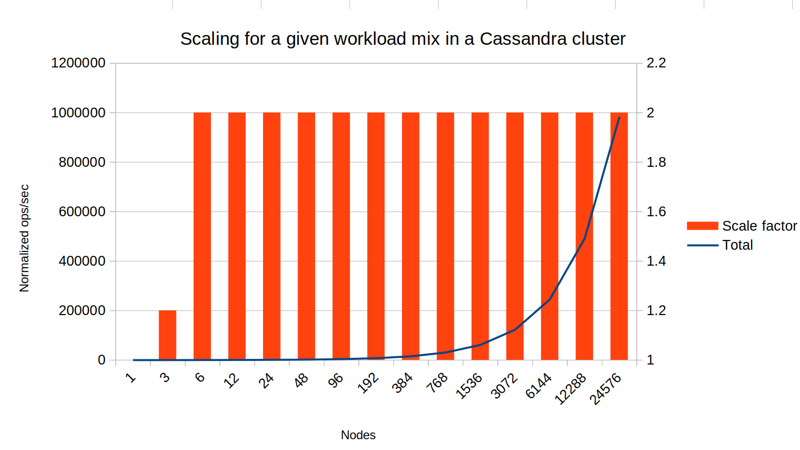
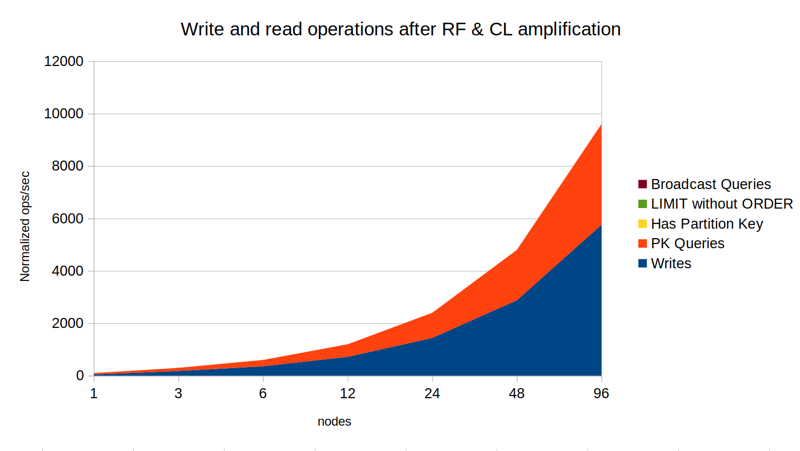
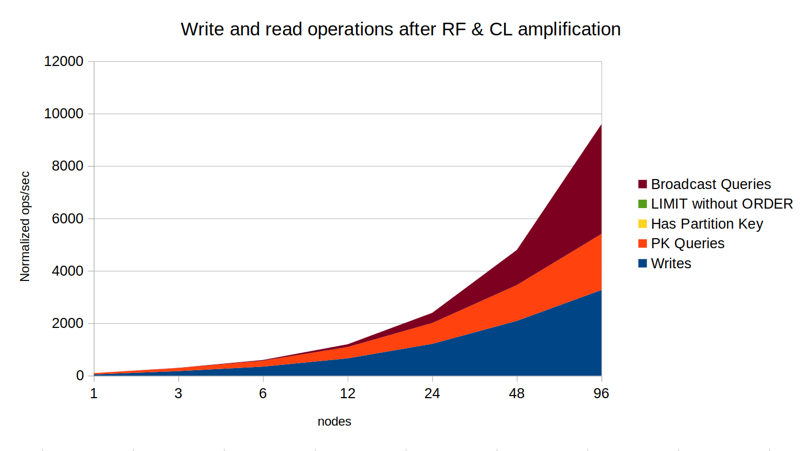
With a 50-50 workload, there's a bit of a surprise. Going from 1 to 3 nodes we actually gain a small benefit! This is because while writes have to be processed by all 3 nodes, reads only have to be sent to 2 nodes. So 3 node cluster can service about 120% of the operations per second that a single node could. The second graph also shows how the writes account for about 60% and reads only 40% of the work done on each node. Note that this is despite the workload from a client point of view is an even 50-50.
Overall this is all just primary key access, and therefore we are still seeing linear scaling. But the above already shows how different types of operations cause different amount of work to be done on each node.
Now, let's add some secondary index queries that are broadcast to all nodes. We are mindful about scalability, so we have designed a workload which is still largely primary key based, (or at least include the partition key) and only 1% of queries need to be broadcast to all nodes:
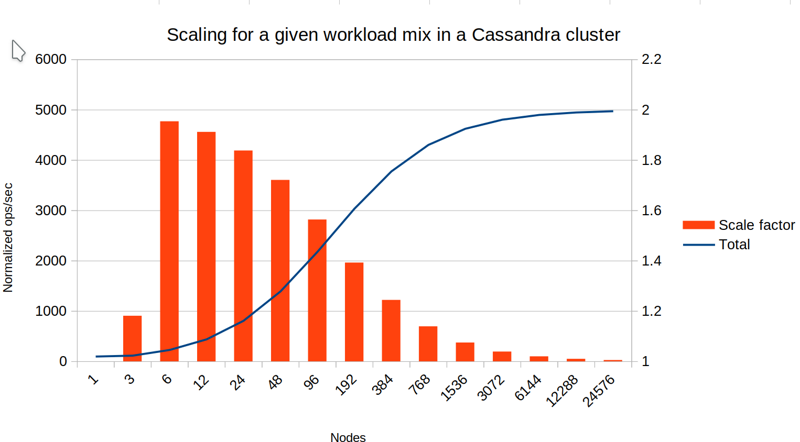
We no longer have linear scalability. But for this workload we can still achieve (asymptotically) 50x more performance compared to the single node case.
In the second graph we can see how the broadcast queries that start as just 1% of the workload, actually become 50% of the work on each node once you approach 100 nodes. Still, for smaller node counts like 12 and 24, this workload still scales well and is a good example of a workload where you can combine a modest use of secondary indexes with a scale out strategy. Probably somewhere at 96 or at least 192 nodes you are at the point where the economics of further adding more nodes no longer makes sense, since you'll get less than 50% performance increase for a 100% increase in infrastructure cost.
Below is the same graph, but with 5% of queries of the broadcast variety:
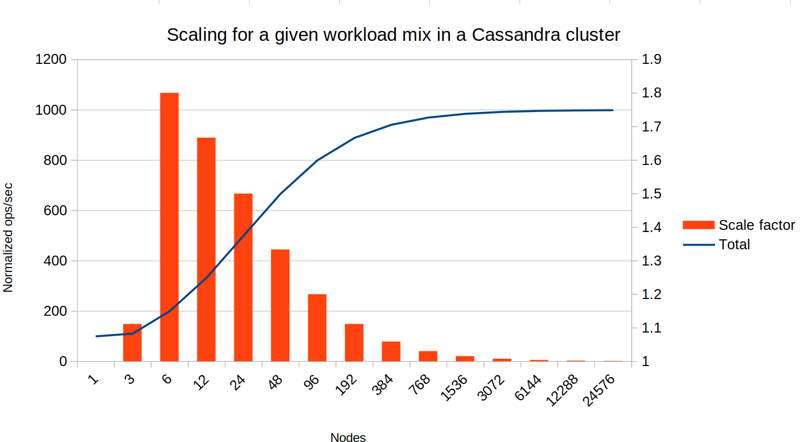
The theoretical maximum for scaling is now only 10x, and after 24 nodes the benefit of doubling your cluster size is less than 50%.
Finally, let's consider a read heavy workload with up to 10% of queries broadcast to all nodes:
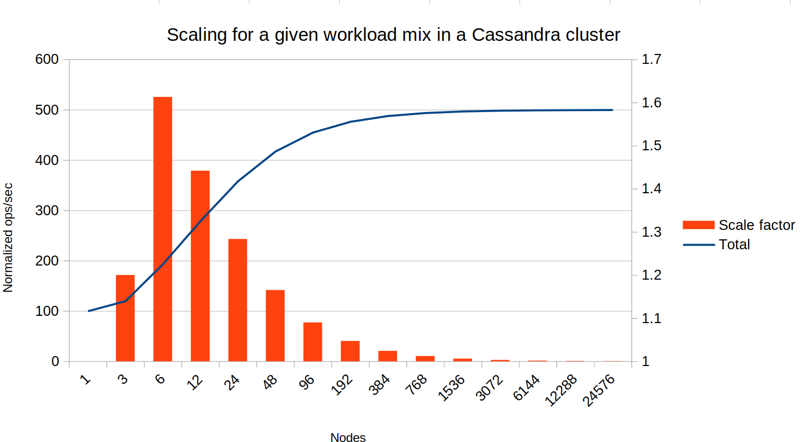
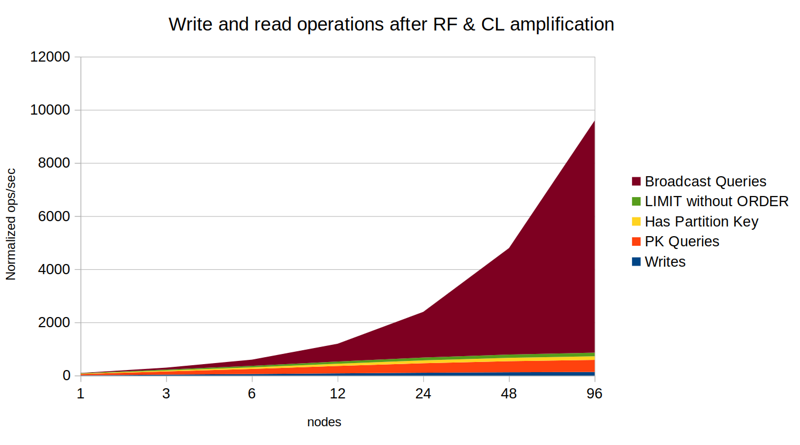
Now already at 12 nodes we've hit the threshold where further doubling of the cluster yields less than 50% performance improvement. If you tried to scale this workload to 96 nodes it would be pointless: 89% of the work on each node would be from broadcast queries, out of which 81% is overhead.
Conclusions
In conclusion, heavy use of queries that use secondary indexes without including the partition key do indeed prevent linear scalability. A best practice would be to keep such queries below 10% of all reads and writes in the workload. Majority of your reads should still use the primary key for access, or at least include the partition key.
For workloads where 1-10% of your queries are broadcast to all nodes (because they don't include the partition key, nor a LIMIT clause) then you can still get some benefit from adding nodes to your cluster. You can use cluster sizes from 12 to 96 nodes meaningfully without ridiculous amounts of overhead.
There are also other benefits from adding more nodes to a cluster, which are not captured by this model. These include having less data per node and fitting more data in RAM.
- Log in to post comments
- 809 views