The thing I really like with open source is the feeling you get when people just show up from nowhere and do great things to some code you originally wrote. Thanks to this miracle, I can now also present to you version 0.2 of the Drizzle JSON HTTP support, featuring a "pure JSON key-value API" in addition to the original "SQL over HTTP" API in 0.1 version. Let's recap what happened:
- At Drizzle Day 2011, I proposed that Drizzle should make available a JSON NoSQL interface. Stewart took the bait and published json_server 0.1 a week later. This API still uses SQL, it's just that the client protocol is HTTP and JSON, into which the SQL is embedded. So I suppose it's not as sexy as real NoSQL, but pretty cool nevertheless.
- At the end of last Summer I had a lot of dead time so I started playing with Stewart's code to see what I could do. I added a new API in addition to Stewart's SQL-over-HTTP API that supports key-value operations in pure JSON, similar to what you see in CouchDB, MongoDB or Metabase. I got it working quite well, however, I never implemented a DELETE command, because I then drifted off to more important tasks, such as revamping the Drizzle version numbering and bringing DEB and RPM packaging up to date.
- Last week a new but very promising Drizzle hacker called Mohit came by, looking for things he could do. He had already fixed a simple low-hanging-bug and wanted something more. Since he was interested in the JSON API, I asked if he wants to finish the missing piece. With my helpful advice of "there is no documentation but if you look at the demo GUI you'll probably figure it out, then just look at the code for POST and implement DELETE instead". I was afraid that wasn't really helpful, but I was busy that day. No problem, the next day Mohit had pushed working DELETE implementation. The day after that he implemented the final missing piece, a CREATE TABLE functionality. I was both impressed and excited.
Note that the upcoming Drizzle 7.1 release only contains HTTP JSON interface 0.1, aka Stewart's code. The new pure-JSON interface is available as a bzr branch at lp:~hingo/drizzle/drizzle-json_server-keyvalue and will be pushed into Drizzle 7.2 Greenlake tree soon.
Btw, I will talk about all this at the upcoming Drizzle Day on Apr 13th.
But while waiting for that, let's take a look at what this baby can (finally!) do now:
Starting Drizzle with JSON Server
This is an optional plugin, so you need to enable it when starting drizzled:
sbin/drizzled --plugin-add=json_server
The demo GUI
With that, you have a HTTP server listening at port 8086. If you point your browser to it, you will see a simple GUI that you can use to explore JSON Server:
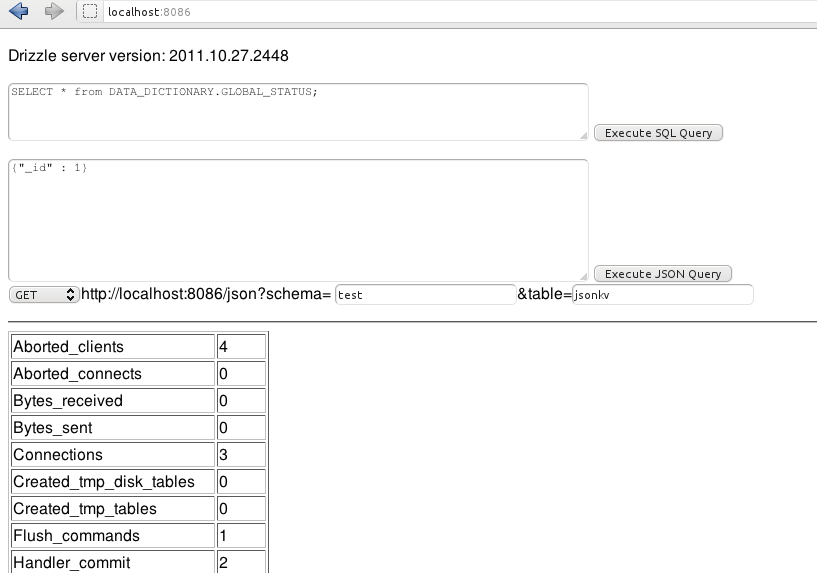
I've added a second query window. To use the SQL API from 0.1 version, use the top text area. This will send your SQL to the API at https://localhost:8086/sql.
To use the new JSON key-value API, use the second text area, which will talk to https://localhost:8086/json. As this is now a true REST API, you also need to select from HTTP methods GET, POST or DELETE. (Turns out PUT doesn't really add any value, so it is currently not implemented. It might just become a synonym of POST one day.)
Creating a schema
Before we can do sexy NoSQL queries into our Drizzle database, the administrator needs to create a schema for us. Conveniently, we can use the text area for the SQL API to just do:
drizzle -e "CREATE SCHEMA json"
I tried typing that into the text area for the SQL API, but I got an error "Transactional DDL not supported". (No biggie, I consider it a triumph that it didn't crash or anything :-)
POSTing a JSON document
Notice the new verbiage! We are going to POST something, not INSERT. And it is going to be a document, not a record. Welcome to REST and JSON.
The idea with a key value store is that you have a key, and the rest can be pretty much anything. In Drizzle JSON API, your key is the _id field and it must be an integer (BIGINT, to be precise.) If you omit it, Drizzle will assign an auto_increment key. However, currently you'd be in trouble because there is no way to get to know the key, we need to implement a last_insert_id() call some day. (I'll reflect over some design decisions in a separate blog post, but MongoDB users will recognize that the choice of key name is not an accident, otoh unfortunately the ID's in MongoDB are not integers, so it is not that compatible after all.)
While it is true that "the rest can be anything", I will now introduce a best practice of putting the rest of your document under a key called "document". So let's now POST the following JSON:
{"_id" : 1,
"document" : { "firstname" : "Henrik",
"lastname" : "Ingo",
"age" : 35
}
}
Remember to choose POST method and set the parameters to the URL correctly: https://localhost:8086/json?schema=json&table=people
I'll repeat that for a few other names so there are more than one documents in the table.
Querying the table
If you just do GET on a table without any JSON query, you get the full table listing. This is probably a bad idea for anything but small tables. (The current implementation will stuff the entire result set into a boost vector at least twice before returning it to you.) But we'll use it to print out the contents of our table:
GET https://localhost:8086/json?schema=json&table=people
| _id | document |
| 1 | {"age":35,"firstname":"Henrik","lastname":"Ingo"} |
| 2 | {"firstname":"Stewart","lastname":"Smith"} |
| 3 | {"age":21,"firstname":"Mohit","lastname":"Srivastva"} |
(The demo GUI doesn't actually print the table headers, I added those here.) That is the table as it is stored in Drizzle. Actually what is returned over HTTP is one complete JSON document:
{
"query" : {
"_id" : null
},
"result_set" : [
{
"_id" : 1,
"document" : {
"age" : 35,
"firstname" : "Henrik",
"lastname" : "Ingo"
}
},
{
"_id" : 2,
"document" : {
"firstname" : "Stewart",
"lastname" : "Smith"
}
},
{
"_id" : 3,
"document" : {
"age" : 21,
"firstname" : "Mohit",
"lastname" : "Srivastva"
}
}
],
"sqlstate" : "00000"
}
In fact, in this case the result_set and sqlstate parts are identical to what you'd get from using the /sql API endpoint too.
Querying a single key
There are two ways to query a single record/document using the _id key. First, you could choose the GET method and provide a query document:
{"_id" : 1 }
Will return
| 1 | {"age":35,"firstname":"Henrik","lastname":"Ingo"} |
Or, full contents of what was sent over the wire:
{
"query" : {
"_id" : 1
},
"result_set" : [
{
"_id" : 1,
"document" : {
"age" : 35,
"firstname" : "Henrik",
"lastname" : "Ingo"
}
}
],
"sqlstate" : "00000"
}
Using a query document is a bit boring for a key-value API, but the thought is that it can be extended in the future to support more complex queries.
The alternative way, which is quite straightforward as long as we are talking key-value stores, is to specify the _id as a parameter in the URI. This could be useful in a number of ways, but one thing that comes to mind is when using CURL or WGET (or you could just copy-paste an URL into your browser) to get:
$ curl 'https://localhost:8086/json?schema=json&table=people&_id=1'
{
"query" : {
"_id" : 1
},
"result_set" : [
{
"_id" : 1,
"document" : {
"age" : 35,
"firstname" : "Henrik",
"lastname" : "Ingo"
}
}
],
"sqlstate" : "00000"
}
$ curl 'https://localhost:8086/json?schema=json&table=people&_id=2'
{
"query" : {
"_id" : 2
},
"result_set" : [
{
"_id" : 2,
"document" : {
"firstname" : "Stewart",
"lastname" : "Smith"
}
}
],
"sqlstate" : "00000"
}
$ curl 'https://localhost:8086/json?schema=json&table=people&_id=3'
{
"query" : {
"_id" : 3
},
"result_set" : [
{
"_id" : 3,
"document" : {
"age" : 21,
"firstname" : "Mohit",
"lastname" : "Srivastva"
}
}
],
"sqlstate" : "00000"
}
Another benefit of having the key in the URL would be for things like sharding. Imagine you have a sharded database in a few Drizzle instances. You could now very easily just use a normal HTTP proxy and configure it to route your queries to the correct shard just using the value in the _id parameter. In fact, even when we one day enable more complex queries, this will be a good reason to support having the primary key in the URL.
UPDATEing a record
To UPDATE, you just POST a new version of the JSON document with the same _id as an already existing record. Try for instance:
{"_id" : 1,
"document" : { "firstname" : "Henrik",
"lastname" : "Ingo",
"age" : 36
}
}
Note: REST purists would require you to use PUT for updates and POST for inserts. To me it is all the same - I use the MySQL/Drizzle specific REPLACE INTO command so I simply don't care whether you intend to insert or update, the right thing will happen anyway. PUT method for HTTP currently doesn't do anything - as it is not idempotent I'm not convinced it's a good idea to use it, but maybe I'll enable it one day for completeness sake.
DELETEing a record
DELETE is a bit boring, since there is so little feedback:
$ curl -X DELETE 'https://localhost:8086/json?schema=json&table=people&_id=3'
{
"query" : {
"_id" : 3
},
"sqlstate" : "00000"
}
But it was deleted, you can't find _id=3 anymore:
$ curl 'https://localhost:8086/json?schema=json&table=people&_id=3'
{
"query" : {
"_id" : 3
},
"sqlstate" : "00000"
}
(No result_set)
Automatic CREATE TABLE
Congratulations if you have read all the above and was still wondering how the table appeared in the first place. In the beginning we created a schema, but never a table. The answer is, it is automatically created by the First POST. (Hehe, didn't even realize how funny that is for a Slashdot generation :-)
This is what the table looks like:
drizzle> show create table people\G
*************************** 1. row ***************************
Table: people
Create Table: CREATE TABLE `people` (
`_id` BIGINT NOT NULL AUTO_INCREMENT,
`document` TEXT COLLATE utf8_general_ci,
PRIMARY KEY (`_id`) USING BTREE
) ENGINE=InnoDB COLLATE = utf8_general_ci
1 row in set (0.000834 sec)
drizzle> select * from people;
+-----+-----------------------------------------------------------------------+
| _id | document |
+-----+-----------------------------------------------------------------------+
| 1 | {
"age" : 35,
"firstname" : "Henrik",
"lastname" : "Ingo"
}
|
| 2 | {
"firstname" : "Stewart",
"lastname" : "Smith"
}
|
+-----+-----------------------------------------------------------------------+
2 rows in set (0.000583 sec)
In other words, there is always the _id column that is your primary key, it is added even if not explicitly present in the first POST. All other top level keys, in this case "document" are then used to create additional columns of type TEXT. These columns contain valid JSON: an integer, a quoted string, or a JSON {} or [] array.
- Log in to post comments
- 20648 views
PUT vs. POST
there is a significant difference between PUT and POST that for example affects reverse proxies. Why are you even bothering creating an HTTP interface if you then choose not to follow its principles then you are severely diminish the utility.
Please point out specifically
Please point out specifically what are the problems. We're not all web folk here, much more database people. My main point in starting the json_server plugin was to spur feedback and organically grow something that works well and makes sense both in DB land and Web land.
Stewart: At least for the SQL
Stewart: At least for the SQL API, using POST for everything is correct. What your SQL query does is completely opaque to HTTP. For the JSON API the discussion is warranted and I'm excited to hear someone explain to me why PUT would be a great idea.
yes you are right that i
yes you are right that i guess with the current API it does matter .. but thats mainly because the current API is problematic.
http://localhost:8086/json?schema=json&table=people&_id=3
should rather be something like:
http://localhost:8086/json/people/3
with accept header "application/json"
(note the "json" in the above url would be the name of the schema, not the request format)
once this is also corrected it would become relevant if one uses POST or PUT
Sorry, but I don't see the
Sorry, but I don't see the difference? The parameters can be in the URI path or in the query string, the meaning is the same. With POST you would still need to handle the difference between:
POST http://localhost:8086/json/people/3
POST http://localhost:8086/json/people
Except that it was convenient for the implementation, the use of query string is justified by the thinking that it allows you to drop some components and use defaults. For instance I can do
POST http://localhost:8086/json?table=people (or even the table could have a default value)
but this would be ambiguous:
POST http://localhost:8086/people
I know the header is wrong, also for the returned content-type it is still text/html.
Appreciate your comments, please keep 'em coming.
The difference is that GET
The difference is that GET parameters should not define what resources you are accessing, but only what "variation" of the resource you want.
So GET parameters should be used to affect sorting or limit.
http://localhost:8086/json/people
http://localhost:8086/json/people?sort=name&limit=10
The above URL both deal with the _same_ resource, the only difference is the representation of that resource.
in the same way:
http://localhost:8086/json/people with accept header application/json vs. application/xml
in both cases the same resource is returned, just one as json and the other as xml
now obviously you could say that http://localhost:8086/json is one resource and each table etc is just a different representation. however i hope we can agree that this isn't the granularity a user would expect
also again .. you want to
also again .. you want to offer the users a canonical URL
if you allow both http://localhost:8086/json?schema=json&table=people and http://localhost:8086/json/people .. then a reverse proxy in front wouldn't know that both are pointing to the same resource and therefore it would end up caching the same content twice.
I'd say your differentiation
I'd say your differentiation above makes some sense, however now you've completely left out the key value to be used for the query. To me, that is on the query string side. For instance, in the future the API will support fetching more than one record. So clearly the table is the lowest granularity that could be called a "resource".
In couchdb on the other hand, the key is part of the URI path. But they are strictly key-value, so it works.
My original point still stands though. It is possible to allow the sysadmin specify both a default schema and a default table. Then the client can indeed just insert whatever objects into http://localhost:8086/json This is only possible if table and schema are not part of the path. I know it doesn't conform to generally accepted "style", but the current implementation actually allows more options.
A default schema and table
A default schema and table should simply be a redirect rule.
As for returning multiple records, sure that would be a search on the given resource via a GET parameter, but given that in most cases you will be working off a table with a PK. Now what I do see as a somewhat valid argument would be tables with multiple column PK's, but I am not sure how your current API would handle that either.
REST idioms and Drizzle JSON API continues...
Ah, now we are getting to interesting questions! Let's take one at a time...
A default schema and table should simply be a redirect rule.
But this is not the problem. I can redirect or I can just map the incoming request to the defaults, that is trivial. The problem is that URL becomes ambiguous. We don't know what this means:
GET http://localhost:8086/people/3
Is the client asking for:
* schema=people&table=default&id=3
* schema=default&table=people&id=3
* schema=people&table=3
I could enforce additional rules to resolve the ambiguity, such as not allowing defaults at all, but didn't want to do that.
As for returning multiple records, sure that would be a search on the given resource via a GET parameter, but given that in most cases you will be working off a table with a PK.
Fair enough. It could be possible to do both: Have the id as part of the URL for a PK lookup, but move it to query_string for more complex queries.
Now what I do see as a somewhat valid argument would be tables with multiple column PK's, but I am not sure how your current API would handle that either.
Or any queries with multiple columns / multiple search attributes. (They don't need to be part of PK, we could just filter on any column / key.)
This is currently not supported. It will be and the API for specifying such queries is up for discussion. (Watch drizzle-discuss if interested.)
ok sorry. here is a good link
ok sorry. here is a good link that explains it http://jcalcote.wordpress.com/2008/10/16/put-or-post-the-rest-of-the-st…
Hi Lukas. Thanks, that's
Hi Lukas. Thanks, that's indeed a good and detailed post.
So my problem with PUT is that it seems to assume that there is only a single client operating against some resource. Of course in that case you can do "PUT as in UPDATE" five times in a row and the end result will be the same, since it is the same update. But what if two clients do:
client1: PUT _id=1 foo
client2: PUT _id=1 bar
client1 reissues: PUT _id=1 foo
Obviously in this case it does matter whether client1 does 1 or 2 operations.
But I do get the point that the above will not result in two or three different records all having _id=1, whereas POST is clearly used to Create records without specifying _id. Otoh if you use POST with _id, and I see no reason why I wouldn't allow that, then it is the same as PUT/Update, just that user agent will issue a warning if you re-run some operation.
concurrent requests that
concurrent requests that change the same resource are a different matter. of course you never have a guarantee that no other user is messing with the resource. the key thing is that if you stick something in front of your server that all requests need to pass through is that if it can rely on your following HTTP principles, it can optimize behavior.
PostgreSQL
you might also want to check out http://wiki.postgresql.org/index.php?title=HTTP_API
Thanks! Worth following.
Thanks! Worth following.