A while ago Baron blogged about his utter dislike for MMM, a framework supposedly used as a MySQL high-availability solution. While I have no personal experience with this framework, reading the comments to that blog I'm indeed convinced that Baron is right. For one thing, it includes the creator of MMM agreeing.
Baron's post still suggests - and having spoken with him I know that's what he has in mind - that a better solution could be built, it's just MMM that has a poor design. I'm going to go further than that: Personally, I've come to think that this family of so called clustering suites is just categorically the wrong approach to database high-availability. I will now explain why they fail, and what the right way is instead.
Clustering suites = FAIL
There are quite a few solutions out there that are so called general clustering suites: Heartbeat 1 and 2, MMM, Solaris Cluster... there is something similar for Windows and several proprietary 3rd party solutions for the Unix world have existed. The newest kid in town is a quiltwork of components called Pacemaker, Corosync and Heartbeat scripts - this has apparently replaced Heartbeat as the canonical Linux solution. (You often see this solution combo called "Pacemaker", which I don't understand why, because it's really Corosync that you start as a daemon that then calls all the other components.)
The following picture shows how a database high-availability setup would be implemented with any of these clustering solutions:
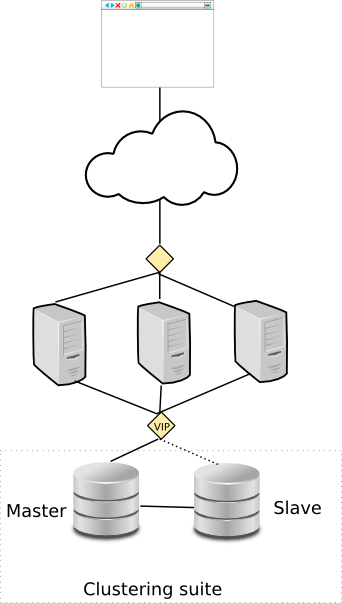
The general approach is to setup 2 (or more) database nodes, with some form of replication. The clustering solution does not replicate the data for you, but it can often support your choice of MySQL replication, DRBD, SAN, etc... In startup, and failover situations it generally needs manage both the MySQL instance itself, and the way data is being replicated. It does this via a special MySQL agent which knows how to start, stop and monitor MySQL. Similarly these general purpose clustering solutions then ship other agents that can manage Tomcat, PostgreSQL and so forth...
So what these clustering frameworks do, is to probe at MySQL from the outside to determine if MySQL still seems to be healthy. In practice you always have a master-slave kind of setup where you are mostly interested in probing the master, but of course the framework is also doing some checks to verify that the slave / standby node is available, in case we should need it later.
If the clustering framework notices that the master MySQL instance is not responding, it initiates failover procedures to the standby node (the slave):
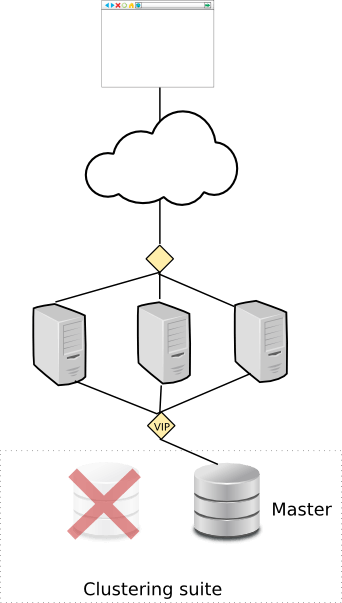
What exactly happens here depends on the setup: for MySQL replication you typically just move the virtual ip to point to the other node, where MySQL is already running. For DRBD and SAN you also need to mount disks and other related activities.
On a picture it seems simple enough. What could possibly go wrong?
To some extent I also share the criticism of Baron: I've now seen a few of these, and these things never convince me as being well designed. Commonly the agents are written as shell scripts similar to your traditional Unix init script. And I just don't think a complex thing like a high-availability solution should be implemented in bash. I recently had a not-so-pleasant encounter with this Pacemaker/Corosync quiltwork, and on a regular startup without errors it prints out 5-7 screenfuls of log messages. That's too much - most users will never find anything useful from such log files. The original xml based way of configuring it seems incomprehensible to anyone, so they've developed a second configuration syntax on top of the "native" one. And despite all those log messages, I still managed to make this thing silently fail on startup without any error message. And so forth... And high-availability is a complex topic - this is not just another text editor someone is developing. So issues like those generally don't give me the confidence that this thing will actually work in production and do the right thing when the network is down.
But that doesn't really matter. Because the main problem here is: no matter how well such a solution would be designed, it still wouldn't work. These things are hacks.
I mean, maybe if you want to use this for starting some stateless application servers, sure. If it detects that your tomcat or apache isn't answering, it can try to restart it for you, and if it fails it will try to start it on some spare node instead. Fine, I see how that could work.
But not for a database. If your MySQL instance crashes, it doesn't help if your choice of clustering software just starts a new instance somewhere else, or randomly moves a vip somewhere else. You actually need to replicate the data to begin with, and when failure happens, the failover needs to be done in a manner that protects your data integrity.
So here's what really happens inside these clustering solutions:
- At a specified interval - the heartbeat - the clustering solution will see if your MySQL instance is still running. The default heartbeat is often something like 10 seconds and minimum granularity tends to be one second. Problem: What happens between these seconds the clustering solution is completely unaware of. If you have 5000 trx/sec, you could have fifty-thousand failures before an attempt to fix the error is made.
- The clustering solution takes small peeks into MySQL from the outside, but other than that MySQL remains a black box. Problem: Say that there are network errors. This causes your transactions to fail, and it also causes replication to fail. So which one failed first? If transactions started failing first, and replication was still working until the end, then you are fine and you can fail over to the other node. But if replication failed first, then you will lose data if you fail over, because not everything was replicated. Your clustering software has no idea, it wasn't looking when the error happened.
- Typically the clustering software itself will have some communication going on, which has the benefit that it verifies that the network connection between nodes is ok. This is in itself useful, sure. Problem: But just like above, if the clustering software detects that network has failed, it's still mostly unaware of the state of MySQL. The failover decision is done blindly.
- In a typical setup like above, the clustering software is actually just checking whether there is a network connection between the two MySQL nodes. If yes, that makes it happy. Problem: Nobody is really checking whether the application servers can really connect to those MySQL nodes! This is one of the most classic errors to make in software programming: when testing for error conditions, you are not testing the thing you actually want to know the answer to, but testing something else. Kind of like the guy in the joke who was searching for his keys under the lamp where there was light, not where he actually lost the keys.
And finally, the point in this architecture where a lot of the problems culminate is the failover decision. In this architecture you typically have one writeable master. When something is wrong with that master, you need to do failover. The failover needs to happen atomically: if you have many application servers you cannot have a situation where some writes are still headed for the old master while others are already happening on the new one. Typically this is handled by using a virtual ip that is assigned to one node at a time. Sounds like a simple solution, but in practice it's entirely possible (for poorly implemented clustering solutions) to simply assign the virtual ip to both nodes at the same time! Robert Hodges has a nice blog posts about problems with virtual ip's.
Often failovers are also expensive, for instance with DRBD and SAN the failover procedure itself includes downtime for restarting MySQL, mounting disks and InnoDB recovery. This brings in the problem of false positives: Often these clustering solutions react to small hiccups in the network and start a failover, even when the situation is then quickly restored. I know of many DBA's that simply gave up on clustering solutions because of too many false positives. After all, your hardware + Linux + MySQL will crash less than once a year. If your clustering software has issues many times a year, it is making things worse, not better.
I firmly believe that this approach simply will not work. The committing of transactions, the replication of data and the detection of failures need to be done together by the same piece of software. You cannot outsource the checking of failures to some external software who checks in every 10 seconds if everything is ok. Also the need for doing any failover at all seems to create a lot of tension between the DBA and his cluster. This needs to be fixed...
Why Galera has none of these problems
The above novel gives a background to why I have been so interested in Galera lately. Let's look at how you'd implement a MySQL high-availability cluster with Galera:
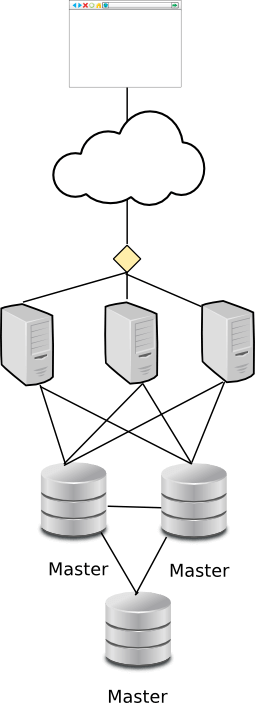
Galera implements synchronous multi-master replication. So the first benefit of this is: there is no virtual ip, and I don't need to choose which node is the master and which are the slaves.
Note that the recommended setup for Galera is to have a minimum of 3 nodes. The third can often be left as a passive reference node not actually receiving connections itself. It is just needed for the cluster to elect a quorum in error situations - you always need to have at least 3 nodes in quorum based clustering.
So what happens when one node fails?
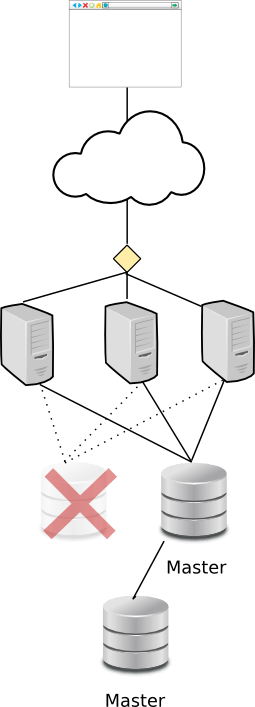
Notice the contrast to the previous list of problems:
- Thanks to synchronous replication and Galera's quorum mechanism, no commits are lost anywhere. When the failure happens, it will be detected as part of the replication process. The Galera nodes themselves figure out which node is thrown out of the cluster, and the remaining ones - who "have quorum" - proceed to commit the transaction. Application nodes that connected to the failing node will of course receive errors as their commits fail.
- There is no need for maintaining master-slave state, virtual ip or to do any failover. The application can connect to any of the Galera nodes and if the transaction succeeds, then it succeeds. If it fails, retry with another node.
- As a side comment: since the replication is synchronous there is no slave lag as you are familiar from MySQL replication, which can also cause you to lose data. This is not a weakness of clustering frameworks, but a strength of Galera compared to classic MySQL replication that most people out there still are using.
But wait, this is not yet the whole story.
We had a really nice lunch with Alex and Sakari from Codership (who produce Galera) before we both went on Summer vacation. So Alex pointed out that users are still not happy with the above. You see, even if we now have good data integrity and don't need to hassle with complex external clustering suites that really are just a bunch of init scripts on steroids... users are not happy, because when a node has failed, the application will continue to try to connect to it and you'll get a lot of connection errors at your application server. So in practice people still use either virtual ip or some kind of tcp/ip load balancer in front of Galera.
And it's not just that that's unnecessary and brings back some complexity that is not really needed, in the worst case those solutions risk bringing back a Single Point of Failure when we've just spent so much effort making MySQL highly available.
It then struck me that I may have been the only person in the world who actually knew that this is already a solved problem. It's no wonder, because the needed JDBC parameter is still not really explained anywhere in the MySQL manual. But the feature is there and a few MySQL Cluster users are using it in production. The best documentation you have is a blog I once wrote. While it talks about MySQL Cluster, the same works as is against a Galera cluster too - these two beutiful products share the same nice properties when it comes to high availability.
So in short, when using a Galera cluster, you should use mysql:loadbalance: in front of your JDBC connection string. This allows you to then give a list of MySQL nodes, which are all writeable masters. The JDBC driver will connect to any one of them and commit the transaction. If a node is not available, it will just try another one. (If a transaction was already in progress, it will fail with an exception, you can then retry it and it will just connect to a new node.) You should read the blog post for details, in particular on how to use the blacklist timeout argument.
The above solution currently only exists for JDBC. I've been following Ulf Wendel's experiments with plugins to the PHP MySQL connector with interest. Even if his team has been focusing on read-write splitting, it seems doing the same for a multi-master cluster is not difficult (hint, hint...).
The beauty of this architecture is not only that it achieves sound data integrity, but also that we have now removed any additional components that are simply not needed anymore. We just have a layer of redundant application nodes and another layer of redundant database nodes, and that's all that's needed. This again proves the principle that the best solutions also tend to be simple solutions. If your solution is complex, you're not doing it right.
- Log in to post comments
- 54954 views
Galera MySQL with a load
Galera MySQL with a load balancer (HAProxy) has been working well for me.
I bet it has! And thank you
I bet it has! And thank you for sharing - I haven't actually run Galera in production myself, yet.
Even if my post argues you don't need the loadbalancer (if you use JDBC, for PHP and others this doesn't really exist yet) if you are using a load balancer with Galera, and until now everyone did that, you are still way ahead what everyone else is doing with MySQL replication and other really suboptimal solutions.
Yeah - using a load balancer
Yeah - using a load balancer makes it a bit easier to make it plug-n-play so to say. No need to redo DB connection support in the app. You could augment it further if you needed to with read/write splitting and have a couple nodes used for writing only and just put that in your load balancer as another IP or another port (3307 or something).
But the point is, the jdbc
But the point is, the jdbc driver includes the loadbalancing functionality if you use mysql:loadbalance: at the front of the connection string. So it does the same thing and you can remove HAprxy as unnecessary. It is similar to read-write splitting, except that it also rotates writes among many servers.
I use HAProxy so it's it's
I use HAProxy so it's it's easy to just change one config setting in an app, instead of having to add in the rest of the stuff. Also, HAProxy keeps an eye on each server, so if one is down, you don't have to worry. Also it creates a central location for adding/removing servers from the LB. You solution works, but if you have 10+ apps using the DBs, it can be a pain to update all the configs. Only draw back is that you can't read/write split natively with HAProxy, and would have to be done at the app level.
So the MySQL JDBC driver can
So the MySQL JDBC driver can do all that. Except you are right, if you want to change the configuration - like add more nodes - then of course you have to do it for each app server. On the other hand, centralized configuration is convenient, but there is a risk you create a new single point of failure. I don't know about HAProxy specifically, just that this has been my experience in general.
I have my HAProxy
I have my HAProxy implementation backed with Corosync/Pacemaker with a simple 2 way rsync on the configuration. So if the main box goes down, the 2nd comes up pretty quickly.
That's the right way to do
That's the right way to do it. (Except, I'm not a fan of corosync/pacemaker either, but at least in theory this is the right way.)
Yeah - Corosync is a little
Yeah - Corosync is a little odd setting up, but it does the job. =)
Good one man, good job,
Good one man, good job, really !
Incredible google
JDBC driver vs. HAProxy
I just ran across your article. This is exactly my thoughts surrounding Pacemaker et al. I have opted to build 2 node clusters with a lightweight garbd node to prevent split brain instead of masters and slaves with autofailover. Thus far, I am using two HAProxy + Keepalived servers running on vm's (the vm's are on running on separate hosts), so no SPOF.
That said, your solution should still not be hard to manage across multiple app servers. I will look into implementing this in conjunction with configuration management software.
Nice article -- gently disagree
Henrik,
I support your views except, that there is a large set of people who use traditional replication due to its benefits, and want to manage promoting a replica for faster recovery times (not really HA). For their business needs, all things considered, it can be a Very Good Solution. (I mentioned some of these use cases in my blog post, which you linked to.)
All of the failure modes you mentioned are possible, but it's also possible for the clustering software to verify whether it's safe to do a failover, and refuse to do so otherwise. Or to do it manually. This is the approach we're taking with the Percona Replication Manager project, which is still in early development. In practice, I expect this to result in the tool refusing to do anything in a great many cases, which is FINE. When that happens, they should call us (assuming they are Percona customers) and a human can safely resolve the situation in a matter of minutes.
But for real High Availability with capital letters, you will hear absolutely no argument from me. Replication isn't it, and these external clustering systems aren't the way to go.
MySQL replication basically
MySQL replication basically runs the web as we know it. So yes, it's not doing that bad. I'm familiar with your argument here.
And yes, part of the problem is that the clustering solutions available don't impress with their design or implementation. I'm sure a solution by you or Yoshinori-san can seriously improve over current state of the art. But even so, your solution will be based on MySQL replication and thus suboptimal.
And of course, until now we didn't have a better solution. Well, MySQL Cluster, but not for InnoDB. Even now, we have something great like Galera but you basically have to patch and compile your own MySQL server. So yeah, no points for ease of use.
At the same time, I've tried Galera, I think it is quite easy to use when you get it ready packaged. There's no binlog positions you have to keep track of. So it's not only better for data durability, I argue people will find it having better usability too. And not only is the replication itself easier to use, it enables you to simplify your architecture. This is a state I want to reach.
As long as someone who ships binaries of a MySQL fork integrates it first - hint, hint :-) - so we don't need to patch MySQL ourselves.
That's the way to do it.
Baron, the approach you're taking with Percona Replication Manager is nothing short of laudable. Indeed, they don't trust computers to dispatch air traffic or supervise children in the kindergarten, yet insist on fully automatic failover or it is not "highly available". Task automation is indispensable of course, but in many cases only a human can make the decision.
There is a catch there though - in the case of some massive failure (like the recent EC2 zone outage), human operators may not be able to cope with all requests on a timely basis. However there's little doubt that they would still do a better job than a fully automated tool.
As for the High Availability with capital letters - that term should be ditched in the gutter as it embodies something as unrealistic and unattainable as "eternal bliss". Better Availability would be more appropriate.
HighER Availability
Right, High Availability is always a matter of degree, not an absolute.
This discussion reminds me of something insightful that Josh Berkus once wrote. He asked and answered the question, "what kind of cluster?" He posits that we should focus more on the users, and less on the technology, which I like. I also agree with his three types of cluster users. They match closely the customers I've worked with.
http://it.toolbox.com/blogs/database-soup/the-three-database-clustering…
Bad users?...
Thanks for pointing to a great article. Very insightful indeed. Unfortunately it highlights the same old "mathematical correctness vs. use case" cognitive gap. Take just one requirement from Transactional User:
To do this with zero data loss and 99.999% or better uptime.
According to CAP theorem this is a pretty tough call. Because 99.999% uptime pretty much means A+P, whereas zero data loss is C. So Transactional User is forced to compromise and that makes him unhappy, and he thinks it is because developers are not trying hard enough to see to his needs. I guess developers tried for decades, but you can't jump the laws of logic, not in programming at least.
Online User is just patently insane. Damn, I wish, I _really_ wish I could make a Solution that would work well for him! But that's impossible. No wonder they are unhappy.
I think that it is high time that the _users_ mend their ways and make few steps towards developers (i.e. distributed computing realities). It maybe in the form of changing their software, or changing their expectations, but it has to be done - or their expectations will never be met. (And usually, when you're in a dead end, you're on a wrong way anyways). And this is exactly why I applauded Percona's human approach which I see as a change of expectations (in this context).
TODO?
BTW, your link to the JDBC blog post goes to a 404 error, I assume because you meant to find the blog post and fix the link before publishing :-)
Thanks for the heads up. Yes,
Thanks for the heads up. Yes, I wrote this long article on a transatlantic flight :-)
MySQL-MHA: "MySQL Master High Availability manager and tools"
And what you can say about the MySQL-MHA? http://yoshinorimatsunobu.blogspot.com/2011/07/announcing-mysql-mha-mys…
I've seen the talk by
I've seen the talk by Yoshinori that this work is based on. He knows what he is doing (just like Baron in this thread knows too). I have no doubt his scripts actually do the right things.
But: He is not even trying to reach the same ambition level I'm laying out here. Yoshinori's solution is based on accepting that some data will be lost during a failure. He is just trying to minimize that loss, and that he does correctly.
In Yoshinori's case I kind of understand him. His disaster scenario is that an earthquake has hit Japan and he must failover to a data center in California. Asynchronous replication is a good solution in that case - although the Galera guys maintain they do pretty well on transcontinental setups too.
Still, since I'm not in Japan, I will continue to pursue my Galera based architecture.
Galera good, tests better
I'm a big fan of Galera and will be working to get people using it ASAP. We still need something for the 1180 of our 1200 clients who use standard replication already :-)
I'm an even bigger fan of automated test suites. Look at Maatkit, Aspersa, basically all of the software I've written; thousands and thousands of tests ensure it's correct and stays correct. I have no doubt that MHA works well for Yoshinori, but there will be bugs when it's used in other use cases, and there's no test suite. (Witness pretty much every third-party patch for MySQL, such as Google's -- lots of bugs when deployed beyond the walls of their original creators, and they are built by excellent engineers too.) An HA solution without a test suite is frightening. It means nothing can be changed with confidence. So although I'm very happy to see the code released, unfortunately it is taking us down a path we've been down a bunch of times -- which is why we keep getting Yet Another Replication Failover System :-( If any of the previous ones had been built to serious software engineering standards, Yoshinori would never have built this one.
The above comment should not be construed as negativity against Yoshinori, his work, or the tools -- I just regret that we still haven't a good implementation of this approach "once and for all."
test suites
Baron,
I have 100+ automated test suites for MHA and have used internally, but haven't released as an open source software yet. This is simply because it is not appropriate to publish yet. Some of tests depend on specific H/W (i.e. power on/off Dell hardware via racadm), and some of test case size is very large to publish(i.e. parsing 1GB x 5 binlogs). Maybe I'll release most of test suites that do not depend on our internal environments in the future.
I fully agree with that automated test suites are very important for software development and I have followed when developing MHA. Releasing test suites as an open source software is also important so that people can safely modify MHA, but I think requirements for patching MHA are much lower than for using MHA.
Great!
Yoshinori, that's great -- thank you for correcting me. Maybe this will be the MMM replacement people have been looking for!
I just had a horrible thought
If Galera becomes a mature replication solution and works well, I might be out of a job. I have made a career out of building tools to manage replication, and I've earned emergency pay many a time for fixing it when it breaks. *sigh*
:-) Supposedly both of our
:-)
Supposedly both of our jobs fall under a title of "performance architect". Why are we so worried about replication then?
mysql:loadbalance: (can we update JDBC configuration dynamical)
As we know we can add n no. of node in Galera Cluster dynamically but can we update same information in JDBC (mysql:loadbalance:)dynamically.
Suppose we have 5 Node Galera Cluster and JDBC is configured for 5 Nodes in loadbalance fashion and i have added 2 another new nodes to cluster. So JDBC should be update with same information of new nodes.
So can we update JDBC configuration without any down time?
That of course depends a
That of course depends a little bit on your application or the framework you use in your application. For the JDBC driver this is just a string and it depends on when in your application code you call DriverManager.getConnection.
Realistically a lot of apps have been written in a way that they do this somehow at startup, and you'd need to restart your application server for new settings to take effect.
The good news is that you could have provided the address of the new Galera nodes in advance, if you know either the hostname or ip address that they will be using. (Note that you could put any hostname into /etc/hosts, so it is possible to have some reserved names for future use.)
So you could start with a 3 node Galera cluster but give the JDBC driver a total of 6 addresses. As only 3 of the addresses would respond, it would start by using those, but later when you add 3 more it would eventually discover that they are now online and start using them too.
XADatasource
Hi does someone knows how can I use mysql:loadbalance: if I am using XADatasource?