2 concepts I've been an active advocate of during the past few years are both supported by Galera: Multi-threaded (aka parallel) slave, and allowing out-of-order commits on such a parallel slave. In trying to optimize Galera settings for the disk bound workload I just reported on, I also came to test these alternatives.
Single threaded vs Multi threaded slave
All of my previously reported tests have been run with wsrep_slave_threads=32. For the memory-bound workload there was no difference using one thread or more, but I left it at 32 "just in case". For the disk bound workload there is a clear benefit in having a multi-threaded slave:
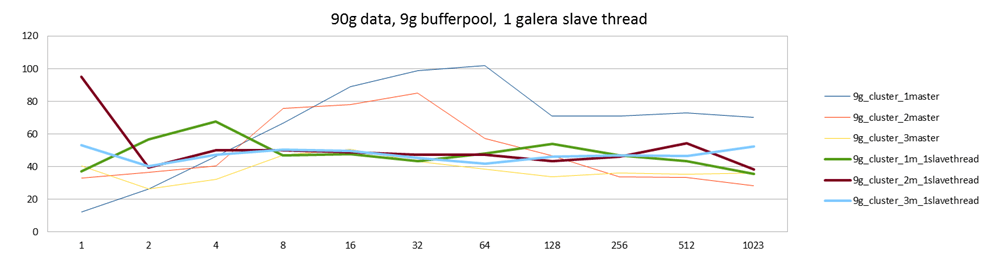
The green, brown and cyan lines were run with a single threaded slave and show a clear decrease in performance. They are also all equal, because they are all limited by the same bottleneck: single-threaded slave. By using more threads on the slave side (blue, red, yellow), we get 2x more performance. This is when writing to only one master, which is the best case for this workload, but I've heard of even 4x improvements due to using multi-threaded slave on other workloads which allow you to also benefit from scale-out to more than one node.
It seems to me Galera team could change the default here to something higher than 1. (Probably 4 or 8.)
Out of order commits
Galera's implementation of multi-threaded slaves is imho the preferred since it allows you to use it on any workload. What happens is that the slave threads can do some work in parallel (most notably, waiting for the disk seeks), but the actual commits are still serialized and happen in the same order as the transactions originated.
So a natural question to ask is, whether it would be beneficial to allow the commits to happen out-of-order, ie just allow each thread to commit independently and as fast as possible?
Before we get to the results, let's ask ourselves, when is this even safe to do? In the general case it is not safe, because you can't have an older transaction writing data in a record that already contains data from a newer transaction. You'd then have old data in that record, and you would also have a slave out of sync with your master. But allowing out of order commits can be safe in some situations:
- If you could also use a conflict resolution function, then a workload that does just single row updates is a good example of a safe workload. In this case the row could contain a column with a timestamp value, and the replication slave is told to only apply transactions where the timestamp is greater than what is already in the database. MySQL Cluster provides this kind of conflict resolution, but Galera does not.
- Even without conflict resolution, some workloads are inherently safe. For instance if you only do reads and inserts, but no updates or deletes.
- Tungsten and MySQL 5.6 allow you to parallelize the replication stream on a per-schema basis, preserving commit order within each schema but not between them. The assumption here is that transactions to different schemas will always be safe, which is in practice true in many cases. AFAICS Galera does not provide this option.
In the sysbench test it is not really safe to use OOOC, but since it is just garbage data anyway, it's worth a try just to see the results:
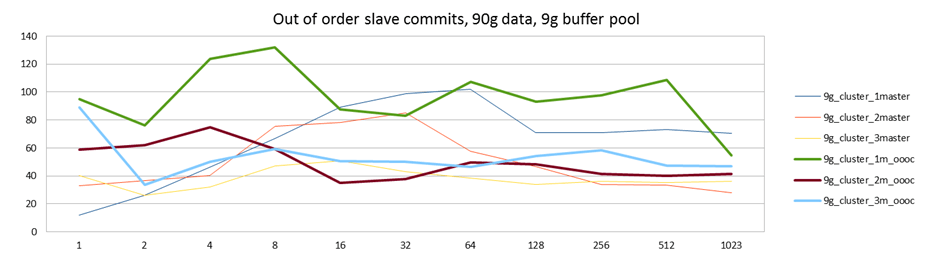
To read these results, you need to compare them one-to-one, ie blue vs green, red vs brown, yellow vs cyan. It makes sense to focus on the best case, which is writing to single master, ie blue and green lines. The others are burdened with other bottlenecks anyway. We see that using OOOC we can indeed increase performance a little. The highest increase is with a low amount of sysbench threads, ie before we saturate the InnoDB/disk layer. However, after we've saturated the disk, out of order commits don't really help. As I explained in the previous post, once you have enough uncomitted events in the replication stream, Galera will make incoming transactions wait anyway, so using OOOC doesn't really help that much, since all of the 32 slaves are just stuck anyway.
Even if there was a small benefit here, it seems there are more important things to focus on than using OOOC, which is only safe in some specific cases. I was surprised to see that just the multi-threaded slave while preserving commit order is so efficient. As it is also a very general solution, it seems like that's the recommended configuration.
Deadlocks
Deadlocks happen when two transactions need to write to two or more of the same rows, and both write to one row first and then both wait for the other transaction to release the lock it's holding on the other row. The only solution in such a case is that one of the transactions is aborted and rolled back, so at least one transaction can continue. This is done by the database and is generally seen as an error (such as Java exception) in the application layer. However, it is a "normal" error, a correctly written application should catch the error and retry the transaction - chances are good it will just succeed the second time.
InnoDB's implementation of MVCC and row-level locks is very nice and user friendly in this regard, so most MySQL users might not have seen a deadlock in their entire life. Other databases may behave differently - for instance I've seen a customer migrating from InnoDB to MySQL Cluster that got into deadlock situation (they were using Hibernate which liked to lock a lot of rows for a long time...) and completely freaked out and blamed MySQL Cluster for it.
Sysbench also reports the amount of transactions that end up deadlocked. Below I've converted these to a percentage of total transactions:
| single_nowsrep_nosyncs | single_nowsrep_syncinnodb_nosyncbinlog | cluster_1master | cluster_2master | cluster_3master | |
| 1 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| 2 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| 4 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| 8 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| 16 | 0.00% | 0.00% | 0.00% | 0.01% | 0.01% |
| 32 | 0.00% | 0.00% | 0.00% | 0.01% | 0.01% |
| 64 | 0.00% | 0.00% | 0.00% | 0.02% | 0.02% |
| 128 | 0.00% | 0.00% | 0.00% | 0.03% | 0.04% |
| 256 | 0.00% | 0.00% | 0.00% | 0.05% | 0.06% |
| 512 | 0.00% | 0.00% | 0.00% | 0.10% | 0.12% |
| 1023 | 0.00% | 0.00% | 0.00% | 0.23% | 0.21% |
This table is for the smaller, in-memory dataset. With the larger data set transactions are spread out over so many rows that there's at most one odd deadlock per each 2.5 minute run.
So, like I said, for a single MySQL node deadlocks simply don't happen. Why do they happen with Galera then?
The way Galera replication works is that a transaction is first executed against the single MySQL node, and committed. When it is committed all write operations are replicated - synchronously, while the commit is blocked - to other nodes in the cluster. At this point Galera now checks if the transaction can also be committed without there being any conflicting locks on those nodes. Usually it can, but it is possible that there is another transaction on that node just running, which is also modifying the same rows. In this case one of the transactions needs to be rolled back.
The difference to a single MySQL node is that there MySQL takes these locks as the transaction proceeds (pessimistic locking), but in Galera this is only the case for the local node, and on remote nodes all locks are taken at commit time (optimistic locking). Indeed, you can see that in the test where we run a Galera cluster but all clients connect to the same master, there are also no deadlocks. They only happen when you write concurrently to several nodes.
So what can you do to overcome this problem? Really, deadlocks are not a problem. Here we see that even under severe stress only 1 transaction in 500 will result in a deadlock, and under normal high concurrency situation it is only 1 in ten thousand - from a performance point of view it is completely negligible. So the only thing you need to do is to diligently catch those Java exceptions and retry deadlocked transactions, as you should. (But I know you don't, so now is a good time to start doing it!)
There could also be some patological workloads where this really becomes an issues. For instance if you had an application that always increments a counter: UPDATE c=c+1 FROM ... WHERE id=1; On a single MySQL node this would result in bad performance, but probably not any deadlocks. However in a Galera cluster I'm sure such an application could cause interesting behavior.
In the worst case, should you find a workload that has problems due to deadlocks, it seems you can always solve it by just writing to a single master.
- Log in to post comments
- 34441 views
Wow! That's too many data in
Wow! That's too many data in one day and will take some time to absorb. Just few quick notes.
1. I see a big dispersion in results - to the extent of being confusing. That's no wonder - we all know how IO can affect transaction execution, and in IO-bound load it is "bound" to happen a lot. It is also quite noticeable that dispersion is much higher towards low client count - exactly because with fewer threads you get fewer samples. Numbers for 1-2 clients hardly make any sense. The point is that perhaps you gotta increase the benchmark time. At least 4x. InnoDB tune-up could also help a lot. I know it may become insanely long, but as it is now it is really hard to see the trend: it is mostly about uneven IO performance.
2. About drop in performance after heating up (previous post). I've seen that many times. I guess the reason is that at first you just have to fetch the pages, and performance grows the more pages you can find in the pool. But once the pool is full, you need to both fetch and flush pages to get space for new ones and you're back to square 1. But I don't think this affects the results from your in-memory benchmarks - there you have just flushing and it does not interfere with fetching.
3. wsrep_slave_threads is 1 by default because with some settings and workloads parallel applying is not safe and could lead to server abort.
4. Performance degradation with increased number of masters (figure 1 here) is rather curious: normally that should happen only if you have high rollback rate. And I think that it is a continuation of a problem seen in your in-memory benchmarks, where innodb performance degrades with increased concurrency. Notice that there is no such degradation when using only one slave thread. There performance is surprisingly even.
1. Yes, agree. I'm trying to
1. Yes, agree. I'm trying to not make too many conclusions from these results. But I think the ones I've made can be made - sorry about the pictures being messy due to too much random variability.
2.With the smaller memory-bound dataset I didn't see these kinds of issues, I'm quite confident about those results.
3. Ok, makes sense.
4. I think it makes sense and have given my view at the end of previous post (ie it makes sense because in Sysbench oltp 100% of transactions include writes). InnoDB of course is part of the problem, but you can't completely blame InnoDB: The total amount of write transactions in the cluster is constant (it is 3x the nr of sysbench clients) regardless of where I write those transactions.
The reason performance is even with 1 slave thread is because it is lower: it is the single-threadedness that becomes a bottleneck. With more wsrep threads Galera is not a bottleneck, but InnoDB and keeping commit order is, and it sets a different limit depending on 1, 2 or 3 masters.
The total amount of write
The total amount of write transactions in the cluster is constant (it is 3x the nr of sysbench clients) regardless of where I write those transactions.
But the total amount of write transactions on one node is still 1x the nr of sysbench clients. And theoretically it should not matter where they come from. And we know that master-slave setup is capable of much more. All the difference is that in multi-master we have less local transactions and more slave pressure.
Anyway, we have not observed anything like this before. Normally IO-bound loads just gave little-to-no scalability. Which was kinda expected: you reached IO limits - you reached the limits on the overall DB modification rate. Of course that's a question to us why it is so different here and whether we can fix it.
Yes: Amount of write
Yes: Amount of write transactions remaining constant explains why you cannot get more performance. Theoretically it could stay the same, but it decreases when you write to more masters. Also 3 masters is worse than 2.
I've thought of some reasons, like if all transactions come in via the same master, they "flow" better and all communication during the commit happens in the same directions, whereas in multi-master they don't: this could add more situations where a commit is waiting for another commit.
Also consider that the selects now run on different nodes (they are not replicated, of course) and affect what is loaded in the buffer pool, so in multi master each node ends up having diverged buffer pools. For a commit to happen "fast" the same page would need to be cached on all nodes. With more masters, the likelihood of that decreases for each added master. Of course, sysbench queries are not uniformly distributed, so probabilistically the buffer pools would eventually converge, but 10% is quite a small bp so I'm pretty sure the difference in what is done with the selects can explain a lot here.