Mark Callaghan pointed me to a paper for my comments: Strong and Efficient Consistency with Consistency-Aware Durability by Ganesan, Alagappan and Arpaci-Dusseau ^2. It won Best Paper award at the Usenix Fast '20 conference. The paper presents a new consistency level for distributed databases where reads are causally consistent with other reads but not (necessarily) with writes. My comments are mostly on section 2 of the paper, which describes current state of the art and a motivation for their work. In Table 1 the authors correctly point out that making database transactions durable by way of replicating them is usually faster than syncing to disk. The last line of the table also makes the point that an even faster option is to neither replicate nor sync to disk synchronously (for example, writeConcern=1 in MongoDB). This is of course correct and obvious, but uninteresting for this blog post and I will ignore this last configuration for the rest of this post. The choice between systems that replicate AND fsync to disk synchronously vs one that merely replicates synchronously is a bit of a religious debate. Many database users and designers feel that data can only be considered durable once it has been written to disk. A more modern school of practitioners claim that replicating to a majority of nodes in the cluster is sufficient. The tagline for this approach is the "writing to remote memory is faster than local disk". More precisely, the latter approach guarantees durability against failures where a majority of nodes are still healthy and can talk to each other. The former approach can be robust against more catastrophic failures than that, but the performance cost is significant. The paper then makes this claim about such majority-committing systems:
Given the cost of synchronous durability, many systems prefer asynchronous durability in which writes are replicated and persisted lazily. In fact, such asynchronous configurations are the default [32, 44] in widely used systems (e.g., Redis, MongoDB). However, by adopting asynchronous durability, as we discuss next, these systems settle for weaker consistency. Most systems use two kinds of asynchronous durability configurations. In the first kind, the system synchronously replicates, but persists data lazily (e.g., ZooKeeper with forceSync[4] disabled). In the second, the system performs both replication and persistence asynchronously (e.g., default Redis, which buffers updates only on the leader’s memory). With asynchronous persistence, the system can lose data, leading to poor consistency. Surprisingly, such cases can occur although data is replicated in memory of many nodes and when just one node crashes. Consider ZooKeeper with asynchronous persistence as shown in Figure 1(i). At first, a majority of nodes (S1, S2, and S3) have committed an item b, buffering it in memory; two nodes (S4 and S5) are operating slowly and so have not seen b. When a node in the majority (S3) crashes and recovers, it loses b. S3 then forms a majority with nodes that have not seen b yet and gets elected the leader†. The system has thus silently lost the committed item b and so a client that previously read a state containing items a and b may now notice an older state containing only a, exposing non-monotonic reads. The intact copies on S1 and S2 are also replaced by the new leader. Similar cases arise with fully asynchronous systems too as shown in Figure 1(ii).
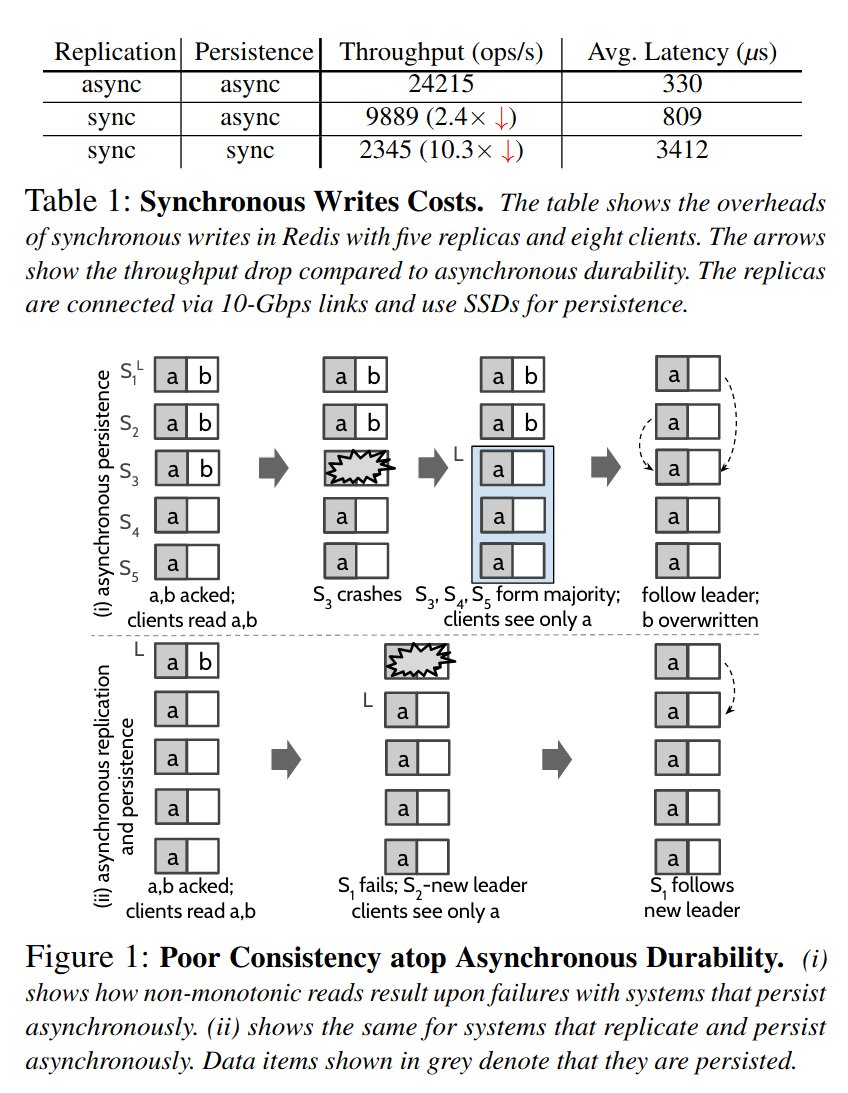 Wait what? This goes against over a decade of experience actually using real world distributed databases that commit via majority replication and defer disk writes to later. What's going on here? (Note again that the last sentence is obvious and uninteresting: asynchronously replicated systems can lose writes by design.) The above example is based on ZooKeeper and if I'm correctly informed, ZooKeeper replication is not based on Raft, rather a protocol called ZAB. That said, as readers of this blog may be most familiar with Raft, I will use Raft + one modification as a well defined algorithm to explain how the above is maybe correct in some abstract academic sense but not in the real world. If you haven't read the Raft thesis, you really should do it anyway. The literal Raft algorithm describes a system where all nodes persist operations to disk, and then report back to a leader. When a majority of nodes have reported back to the leader, the leader returns information to the client that the commit was successful. During failovers an election protocol requires a majority of nodes to agree on a new leader, which guarantees that at least one healthy node has all the majority-committed writes and therefore no writes are ever lost. In the above quoted section Ganesan et.al. assume a system that is like Raft, but the nodes don't immediately write to disk. My claim is that such a system is still robust against any failure of a minority of nodes in the cluster. Ganesan et.al. claim that even just a single node restarting can cause properly majority-committed writes to be lost. Who is right and who is wrong? On a literal reading, the paper is actually correct! A modified Raft as I described above would exhibit this type of data loss. The only crux is that real world databases I'm familiar with do not lose data like that. (Maybe ZooKeeper does, in which case hopefully they can read this post and fix their issue.) Real world databases that I am aware of would also implement a so called pre-vote algorithm before the actual majority election is allowed to proceed. The Raft thesis already mentions that this is a good idea, but doesn't spell out the steps how such an algorithm should be implemented. I have written a post on how to do that in 2015. A distributed database that implements a pre-vote algorithm is not vulnerable to the data loss described above. What would happen when S3 restarts and calls for an election is that S4 and S5 will respond with: "No thank you, we're fine, S1 is still the leader and you should follow them." Crisis averted! (For example, MongoDB implements a pre-vote step in its failover algorithm and would behave like this.) Updates: In correspondance with Ganesan I've learned that ZAB is similar to Raft as far as the above example is concerned. It is designed to use sync-to-disk, but Zookeeper allows users to turn that off. Ganesan also pointed out that a 2012 upgrade to Viewstamped Replication does not require nodes to fsync replicated transactions. The Recovery phase of VR is indeed similar to above suggestion. See comments for more discussion on this.
Wait what? This goes against over a decade of experience actually using real world distributed databases that commit via majority replication and defer disk writes to later. What's going on here? (Note again that the last sentence is obvious and uninteresting: asynchronously replicated systems can lose writes by design.) The above example is based on ZooKeeper and if I'm correctly informed, ZooKeeper replication is not based on Raft, rather a protocol called ZAB. That said, as readers of this blog may be most familiar with Raft, I will use Raft + one modification as a well defined algorithm to explain how the above is maybe correct in some abstract academic sense but not in the real world. If you haven't read the Raft thesis, you really should do it anyway. The literal Raft algorithm describes a system where all nodes persist operations to disk, and then report back to a leader. When a majority of nodes have reported back to the leader, the leader returns information to the client that the commit was successful. During failovers an election protocol requires a majority of nodes to agree on a new leader, which guarantees that at least one healthy node has all the majority-committed writes and therefore no writes are ever lost. In the above quoted section Ganesan et.al. assume a system that is like Raft, but the nodes don't immediately write to disk. My claim is that such a system is still robust against any failure of a minority of nodes in the cluster. Ganesan et.al. claim that even just a single node restarting can cause properly majority-committed writes to be lost. Who is right and who is wrong? On a literal reading, the paper is actually correct! A modified Raft as I described above would exhibit this type of data loss. The only crux is that real world databases I'm familiar with do not lose data like that. (Maybe ZooKeeper does, in which case hopefully they can read this post and fix their issue.) Real world databases that I am aware of would also implement a so called pre-vote algorithm before the actual majority election is allowed to proceed. The Raft thesis already mentions that this is a good idea, but doesn't spell out the steps how such an algorithm should be implemented. I have written a post on how to do that in 2015. A distributed database that implements a pre-vote algorithm is not vulnerable to the data loss described above. What would happen when S3 restarts and calls for an election is that S4 and S5 will respond with: "No thank you, we're fine, S1 is still the leader and you should follow them." Crisis averted! (For example, MongoDB implements a pre-vote step in its failover algorithm and would behave like this.) Updates: In correspondance with Ganesan I've learned that ZAB is similar to Raft as far as the above example is concerned. It is designed to use sync-to-disk, but Zookeeper allows users to turn that off. Ganesan also pointed out that a 2012 upgrade to Viewstamped Replication does not require nodes to fsync replicated transactions. The Recovery phase of VR is indeed similar to above suggestion. See comments for more discussion on this.
But what about...
A reasonable reader might now ask a follow-up question: What if S4 and S5 are also partitioned from S1, so that they no longer have a leader? Would they now accept S3 as a new leader and cause the data loss as described in the paper? Yes! But this still works as designed, because we now had 3 out of 5 nodes failing. 1 node crashed and 2 other were partitioned, so this means a majority of nodes failed at the same time. The guarantee to be robust against failures of a minority of nodes is not violated. But wait, there's more! What if the leader, S1 fails, loses transaction b, restarts and then calls for an election and becomes leader? Since the leader has failed, the pre-vote algorithm will not prevent S1 from calling an election, getting votes from S4 and S5, and becoming the new leader of a cluster that has lost transaction b. Even this scenario is unlikely to ever happen in the real world, because S1 would have to fail and restart faster than the other nodes will hit their election timeout, which is a matter of seconds. But it nevertheless CAN happen, with however small probability. It's a shame that Ganesan et.al. did not think of presenting this example, because that would have been a ground breaking contribution also in the real world, not just in an unrealistic academic scenario. So additional precaution is needed to prevent data loss when the leader fails in a commit-by-replication cluster. What can we do? The answer is that a crashed node must refrain from participating in the next election. It can neither stand for election nor vote in it. It must wait until there is a leader elected from the healthy nodes, one of whom is guaranteed to have all the committed transactions and then it must rejoin the cluster first as a follower. Only after this can it participate in elections again. This is fairly straightforward to implement, nodes just need to persist to the end of their log a note that they did shutdown cleanly. However, there's an interesting corner case for catastrophic failures: If all (or a majority of) nodes crash, the cluster cannot start again because none of the nodes will call for election. Such a cluster needs to add a command to allow the administrator to manually restart the cluster after such a catastrophic crash. By manually calling this command, the administrator is also acknowledging that the catastrophic failure could have lost data. There's yet one more variation on this failure: If S1 and S3 fail together, it's also possible that S3 can call for election and win it because the other nodes no longer have a leader. The above procedure therefore applies both to S1 and S3. That is, both to leader and follower. (This paragraph added 2020-03-30.)
The rest of the paper
Having spent all of my time and energy just on Figure 1, I kind of just skimmed the rest. So I can't vouch for the new consistency level the paper presents, but assuming it is correct... Cross-client monotonic reads is a consistency level between causal consistency (which provides a linear experience for each client separately) and full (read-write) linearizability. Not being able to read your own writes may at first sound like a weird consistency level to strive for, but it can be useful for at least one obvious class of use cases: applications where some threads only write to and other threads only read from the database. The paper mentions an increasing counter (of likes, say) as one example. Also various monitoring and other IoT use cases would fit this definition. While this post was focused on synchronous replication with asynchronous disk writes, it is worth emphasizing that the new consistency level is still valid and a useful contribution to applications that want to use asynchronous replication with asynchronous disk writes. Many IoT and monitoring applications can tolerate a small (and sometimes large) amount of data loss, and providing a relatively strong consistency for reads is a welcome invention.
Conclusions
Since Raft specifies that nodes must fsync all commits to disk, the alternative where you don't has been less studied. Yet in practice this is a common configuration for real world databases! Ganesan et.al. present a claim that a distributed state machine doing only majority commits without fsync could lose committed transactions due to a mere single node failure. My response is that their example is not something that could actually happen in well designed real world systems. In particular, implementing a pre-vote step will prevent the data loss. However, further analysis shows that data loss is possible if the leader node is one of the failing nodes. To prevent this from happening, distributed databases that only do majority commits need to prevent failed nodes from voting in elections until they have successfully rejoined the cluster. I believe this risk for data loss has not been identified or understood previously and hopefully engineers who implement distributed databases will find this blog post helpful in preventing such data loss. To be clear: fsyncing commits to disk is not necessary to prevent data loss in case of minority of nodes failing.
- Log in to post comments
- 2092 views
Comment on review
This was a very good analysis. Surprising that it passed peer review and became even awarded in the end. Raft is widely known already and ignoring it is surprising.
Is there a study/analysis about Raft-based consensus algorithm which doesn't write terms, or logs to persistent storage before acknowledging but instead, writes to local and distant RAM? Have you considered writing one? It would be neat and interesting.
Thank you Vilho To be clear,
Thank you Vilho
To be clear, Ganesan et.al. do reference Raft in their references, it's just that this claim wasn't based on Raft. I "retrofitted" that to have a well defined algorithm (Raft minus fsyncs) to argue about.
Saying "ZooKeeper" is perhaps well defined too, but leaves open the question whether the problem is with the algorithm or Zookeeper's implementation of it.
> Is there a study/analysis about Raft-based consensus algorithm which doesn't write terms, or logs to persistent storage before acknowledging but instead, writes to local and distant RAM?
I'm not aware of one, but I don't follow academic arena as closely as many others.
Note that I think nodes should fsync terms, election results and for example cluster membership changes. It's not a big cost to do that. Just not each transaction = log entries.
I agree that terms and voting
I agree that terms and voting should be stored persistently and based on the earlier discussion, I can't see why using optimal disk writes (that it, avoid fsync'ing before at commit) would cause more problems that what you described.
By the way, your idea about how to prevent data loss in case of Leader fails and loses RAM-committed trx : "The answer is that a crashed node must refrain from participating in the next election" might have more useful cases as it seems also solve the case (presented in raft google group) where node fails, loses all data but recovers and gives its vote for candidate who's not up-to-date.
We wrote a paper on performance measurement of HSB databases where different commit models were compared (Wolski, Raatikka 2006) and I was hoping that someone would feel enough interest to spread similar information about this bit more complicated environment.
Vilho
Well, I have to take back
Well, I have to take back what I said about applicability of your idea on that one particular problem described in discussion thread 'Safely recovering from a "nuked" node'. When it got clearer what it is about I don't think Raft is the right tool for solving it. Interesting discussion, though, especially when it is also said that it is almost not possible to make such a cluster automatically managed :-)
Vilho
Re: Nuked nodes on Raft google group
I've been following the discussion on the Raft list, but didn't want to hijack the discussion just yet. I think it is a related topic in the sense that the same fixes would apply.
Although they haven't commented here yet, the authors of this paper pointed out by email that a 2012 update to Viewstamped Replication is like Raft but without fsyncs. It describes a recovery procedure that safely handles the failure scenarios that can happen here. Essentially the recovery procedure is the same as described in this blog post. https://www.freecodecamp.org/news/viewstamped-replication-revisited-a-s…
Thanks, good discussion, and
Thanks, good discussion, and reading for the Easter.
Happy holidays and be well.
Vilho
Author response
Hello Henrik,
I am one of the authors of the paper "Strong and Efficient Consistency with Consistency-aware Durability." We really appreciate your interest in our work and thank you for taking the time to write the post!
We also had a useful conversation with you (via email correspondence). We are glad that we could discuss our work in detail with an industry expert and learn about MongoDB's use of pre-voting. We want to share our thoughts about some of the points in the post here.
We first discuss the synchronous replication + asynchronous persistence example scenario (in Figure-1(i)), which seems to be the primary focus of the post. The post notes that in the example when S3 crashes and recovers, it should not be able to get votes from S4 and S5 if the system uses something like pre-voting. We agree with this point: with pre-voting, S4 and S5 would not give their votes, averting the problem. However, the paper does not say that S3 will immediately get votes from S4 and S5. But, what it says is that it is *possible* that S3, S4, and S5 can form a majority. For example, if the current leader gets partitioned, then S3, S4, and S5 could form a majority in a subsequent term/view.
The post also mentions that we claim that only one node has to fail to expose the data-loss problem in the example. Note that the paper says that only one node has to *crash and recover* (not fail) to trigger a data loss. For instance, in the scenario described in the above paragraph, only one node crashes and recovers while the leader gets partitioned.
The post also mentions that we do not show the case where the *leader* crashes after the update is buffered on a bare majority. In such a case, pre-voting would not work as the post correctly points out. We agree that showing this example would have been interesting. Although we do not show this in Section-2, we have been aware of this case since our prior work in 2018 [2, 3]. Further, our cluster-crash testing framework (described in Section-5.3) does include tests where the leader crashes after the updates have been buffered on a bare majority. Our experiments, as a result, do expose inconsistencies (because of an underlying data loss) in such cases.
The post notes that data loss can be avoided if the system is careful about crash recovery. We agree with this point. A well-known approach to avoid data loss is to use something like Viewstamped Replication's (VR) recovery protocol [1]. With this, a node that crashes and recovers cannot participate in view change (leader election) and consensus (accepting new requests) immediately, preventing the data loss. This approach is very similar to what the post describes. We note that the paper does indeed point this out. However, one might have understandably missed this because it is in the footnote of Section-2.2. Our prior work discusses these approaches in much more detail [2, 3, 4].
You mention many database practitioners believe that systems that do sync replication + async disk writes are not prone to data loss. We agree with your point: if a system does sync replication + async disk writes, and *if it is careful about crash recovery*, then it is not prone to data loss. However, a system that does not recover carefully can lose data. You made a good point, however (in our email exchange): these systems/configurations must be explicitly called asynchronous, and the solution is to use VR to avoid data loss. However, we believe our new durability model can still be useful for a system that employs sync replication + async disk writes + VR recovery as we discuss below (this is not something we discussed in the paper.)
The problem with VR is that if a majority of nodes crash, the system will remain unavailable even after all nodes have recovered. As the post mentions, one way to fix this problem would be to have the administrator do a repair after such failures. However, the problem with this approach is that the system can *arbitrarily* lose any data: specifically, even data items that have been read by clients before the failure can be lost, exposing out-of-order states. A system can use CAD along with VR to solve this problem. In such a system, after the repair, we can guarantee that data that has been served to clients will not be lost, ensuring monotonicity, an improvement over base VR.
Overall, our main point is that in a system that does not use VR, if a node crashes and recovers after updates have been buffered on a bare majority, a majority at that point will not have the updates on disk and so the system is vulnerable to a data loss. On the other hand, if a system is careful about crash recovery (e.g., by using VR), then data-loss instances can be avoided, but the system may remain unavailable upon majority failures. Administrator intervention can bring the system back online, but the system could have arbitrarily lost any data. A system can use our durability model along with VR to solve this problem.
Thank you again for the blog post. We appreciate you taking the time to write this!
References:
[1] http://www.pmg.csail.mit.edu/papers/vr-revisited.pdf
[2] https://research.cs.wisc.edu/adsl/Publications/osdi18-fastslow.pdf
[3] https://research.cs.wisc.edu/adsl/Publications/osdi18-saucr-slides.pdf
[4] https://research.cs.wisc.edu/adsl/Publications/ram-thesis.pdf
Hei Ganesan
Hi Ganesan
Thanks for reaching out. I've learned a lot from your feedback. In particular, thanks for pointing me to the updated version of VR, I had not realized it has much evolved from the 80's version. As Raft has gotten most of the attention of the database industry the past 5 years, the option to not fsync every single transaction has gotten less attention. I'm really excited there exists a well known academically vetted algorithm we can reference to, and engineers can either use VR or borrow its recovery module.
Inspired by this discussion, I must next go back and more thoughtfully read your previous work Protocol-Aware Recovery for Consensus-Based Storage as well. It seems to discuss this same topic.
This is another interesting direction that I need to read more about. Well defined algorithms that can restore a cluster after a majority, or all, nodes failed without administrator intervention is another area I don't think the industry has fully understood yet and I think your suggestions are interesting ideas here. (Again, the industry standard answer would typically be that you need to use Raft and do the fsyncs.)