July is vacation time in Finland. Which means it is a great time to read blogs and papers on consistency in distributed databases! This and following blogs are my reading notes and thoughts. Mostly for my own benefit but if you benefit too, that's great. Note also that my ambition is not to appear like an authority on consistency. I just write down questions I had and things I learned. If you have comments, feel free to write some below. That's part of the point of blogging this!
This first post is mostly to set the scene that I'm starting from and questions I was wondering about. In follow up posts I will comment on papers I've read. (Spoiler: Serializeable Snapshot Isolation, Calvin and Spanner.)
Remind me: What is linearizeability? Or serializeability for that matter?
Even with old school relational databases understanding and remembering isolation levels is one of the hardest things for a database expert. Sure, I remember that the SQL standard defines READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ and SERIALIZEABLE. But do you remember exactly how dirty reads, phantom reads and write skew happen? And even relational databases aren't easy: Someone invented the MVCC architecture and many databases now implement that and they provide Snapshot Isolation. And it's a great isolation level, even if it is not in the SQL standard. PostgreSQL is MVCC, but wanted to stick with standards compliant syntax, so as a result if you specify REPEATABLE READ, you actually get Snapshot Isolation ((slide 21), and they are not the same thing! So now you see how this can be hard to follow even for the best of us!
With distributed databases a lot of new consistency levels are introduced. Both replication and sharding introduce their own anomalies, for which you can then apply various algorithms to prevent a mess.
Luckily Kyle Kingsbury has created this clickable map of consistency levels. The ones higher up are supersets of the ones below, and therefore better. You can click on each box for a layman understandable explanation of each.
On the left you have the isolation levels familiar from relational databases, while the righ branch deals with consistency issues arising from distributed databases.
MongoDB
My vacation reading was not about MongoDB. Quite the contrary, the whole point was to read about stuff I'm not familiar with from work! So just to share what I am familiar with, below is Kyle Kingsbury's graph and a leaf on top of each consistency level supported by MongoDB.
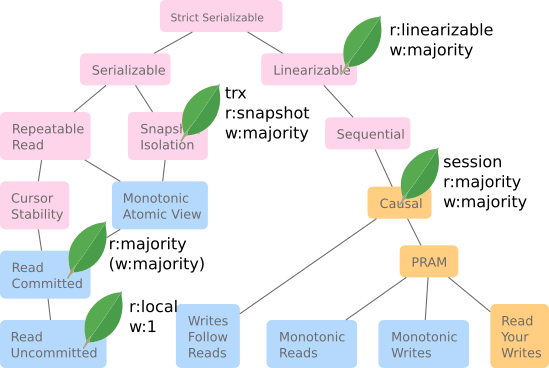
Speaking of being familiar with those consistency levels, last year I got to do a presentation investigating read and write latencies for each of the consistency levels supported by MongoDB.
The transactions supported since 4.0 (4.2 for cross shard) support snapshot isolation AND causal consistency. Linearizeable consistency is also supported since 3.4, but only for single operations and on a per record basis.
Linearizeable vs Causal Consistency
The difference between linearizeable and causal consistency is easy to explain. Causal means that state never goes backward on a per client basis while linearizeable is the same guarantee globally, even for independent observers.
Imagine that I'm on my laptop and update my profile picture on a social media site. When I return to my main feed, I would expect to see the new profile picture. Causal consistency guarantees that this will happen. But imagine then I also open the same social media app on my phone. With causal consistency it's possible that I still see my old profile pic. Linearizeable consistency will guarantee that any device anywhere in the world can only see the new pic.
(If you're thinking that causal consistency sounds a lot like "read your own writes", then yes, it is a superset of that.)
Linearizeable for transactions?
So the first question that arises from the above is: Could linearizeable consistency be supported also for multi-statement transactions? The simple answer turns out to be: No!
So that's that then... Note that an obvious hack could be applied to transactions that kind of does the same for a transaction as what real linearizeable does for single record operations. Since MongoDB is a so called "leader based" replication system, it's kind of linearizeable as it is, if you just read from the primary node in a replica set. The only case where a so called "stale read" anomaly can happen is when a new primary has been elected, and a client still connects to the old primary who allows the read to complete because it doesn't yet know it is no longer a primary. To avoid this issue, linearizeable reads write a no-op write to the oplog and wait for a majority commit to succeed. This guarantees that the primary is indeed still the real primary.
So for multi-statement transactions, that formally only support causal consistency, you could apply the same hack, simply by adding a dummy write to an otherwise read-only transaction. This will surely avoid the stale reads due to recent primary failover, so from that point of view it achieves the same linearizeable-like experience as exists for single record operations. But upon further thinking, it also opens some difficult to answer questions:
- Inside a transaction, not all reads happen at the same time from a wall clock perspective. If I read record A, sleep 2 seconds and then read record B, thanks to Snapshot Isolation those reads will be from the same consistent point in time. (The time of reading A.) But from a global or independent observer perspective, record B is read from a snapshot 2 seconds old. Another independent observer could already have seen a newer version of B. This user experience seems to contradict the whole point of linearizeability and is probably the main reason why linearizeability was not defined for this kind of case at all.
- Sharding introduces its own problems... First of all, one would have to do dummy writes against all shards now, to ensure that each read is non-stale.
- Geographically distributed shards would then be an interesting discussion, if you could get this far... Here the order of events experienced by different clients is impacted by their distance (which translates to latency) to different shards. This is clearly irreconcileable with the experience we're aiming for here and our simple hack of adding writes to read-only transactions does nothing to address this issue.
So what about serializeable?
The paradox with serializeable isolation is that it's the best isolation level of the relational database world, yet in practice nobody ever uses it. PostgreSQL didn't even implement it until 9.1. This is surprising given how much PG devs care about the SQL standard! MySQL (InnoDB) had it since forever, but it's not the default and I can't remember that I ever saw an app actually using it.
The reality is that repeatable read and snapshot isolation are fairly good isolation levels. Especially snapshot isolation is rather easy for a developer to understand: All reads are from the same (valid) snapshot and if two concurrent threads try to modify the same records you hit a lock and the second write is prevented. The cost of locking to handle such write conflicts is reasonable - it's the same as would happen in the developer's own application code too. By contrast, the naive (and common?) implementation of serializeable requires to also lock all records read. For queries like `SELECT COUNT(*) FROM mytable` this is all records in the entire table. In addition to locking all records it also "gap locks" the table so you can't insert new records either. It's easy to see how this will lead to much higher overhead due to aborted transactions. Not to mention annoyed developers who would have to deal with retrying the aborted transactions.
Consider also that SQL also provides `SELECT FOR UPDATE` which allows to lock records on an as-needed basis. In practice then either snapshot or repeatable read together with this case by case locking is what has served the real world well.
So for MongoDB then, it's possible that nobody will ever ask for a serializeable isolation level. (Maybe someone will ask for a SELECT FOR UPDATE equivalent?) But it is an interesting academic question to think about what it would take to implement serializeable (and ultimately strict serializeable) for a sharded database. As with linearizeable, it is easy to see that replica sets are not a challenge: When reading from the primary, the situation is essentially the same as for a classic relational database.
It would be wrong of me to say that implementing snapshot isolation for a sharded database was easy. After all, countless engineers worked several years to make it happen. That said, just like understanding snapshot isolation on a single server was easy, it is quite easy to understand how it works for sharded clusters too. As each shard runs an MVCC storage engine that allows clients to specify a timestamp to read from, all that is needed is to introduce a cluster wide concept of time, so that a client can specify the same snapshot across all shards. Write conflicts are easy to detect because they are per record and therefore local to each shard. As soon as a second transaction tries to update a record locked by another transaction, it is aborted, purely as a local decision.
If the naive implementation of serializeable is to just lock all read records too - and the gaps between them - it seems to me that this could work for sharded clusters just like snapshot isolation does: As soon as you read any record locked by another transaction, your transaction is aborted. We already know from single server databases that nobody will want to use such an implementation, and surely for a distributed database the scalability issues would be even worse. (I assume, but have not verified, that sharding introduces a deadlock-like race condition, where it is possible that both conflicting transactions are aborted by different shards. While aborting the second transaction is unnecessary, it isn't wrong from a semantic / contract point of view.)
To be continued...
So, as a reader you're now caught up to where I started looking for papers to read. I will comment on them in separate blog posts, but this is the list I've been going through:
- Serializeable Snapshot Isolation
- Calvin
- Cloud Spanner
- Log in to post comments
- 13533 views
Discussion on Twitter
On Twitter Ryan Worl and Kyle Kingsbury kindly offer comments, including a podcast about strict serializeability in FoundationDB. Kyle remembers that CockroachDB does prevent stale read-only transactions without going full strict serializeable. So there could be something useful in the space between linearizeable and strict serializeable that doesn't quite have a name yet.