Percona.tv: State of the MySQL Ecosystem
- Read more about Percona.tv: State of the MySQL Ecosystem
- Log in to post comments
- 16091 views
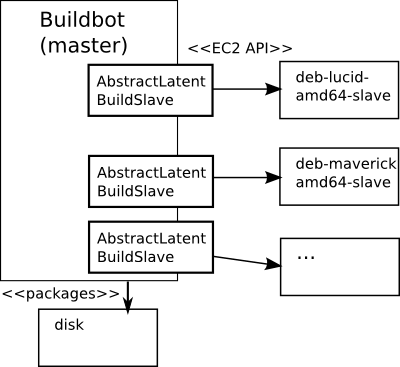
In March I posted a series of blog posts on my paternity leave MepSQL project, which I called MepSQL. There was still one piece created in the MepSQL buildsystem that I didn't publish or blog about. Since it is generally useful, I wanted to generalize and polish it and publish it separately. I finally had that done last week, when I also found that somebody else, namely alestic.com already published a similar solution 2 years ago. So yesterday I ported my BuildBot setup to use that system instead and am happy to publish it at the Open DB Camp 2011 in Sardinia.
Ok, so let's go back a little... What is the problem we are solving?
Let's refresh our memory with a picture (and you can also go back and read about it):
© 2006-2026 Henrik Ingo.
The content on this site is published with the Creative Commons Attribution License.
That means you are free to copy and reuse and redistribute the book, blog posts and other original content you find on this site.
Non-original content will be clearly attributed with their respective copyright terms.
Designed by: Golems G.A.B.B. OÜ
Recent comments
I have…